Published
- 3 min read
From Zero to Building a Production-Grade RAG System (Without Framework Magic)
From Zero to Building a Production-Grade RAG System (Without Framework Magic)
Over the past few days, I went deep into something I had been curious about for a while - Retrieval Augmented Generation (RAG). Not by just reading blogs or watching videos, but by actually building it from scratch, breaking it, debugging it, improving it, and then gradually evolving it into something that resembles a real system.
This post is not a tutorial. It’s a walkthrough of how I understood RAG by building it step by step, the decisions I made, the mistakes I avoided, and how I gradually moved from a naive implementation to something much closer to production-grade.
If you’re someone trying to get into AI engineering, GenAI, or just want to understand how systems like ChatGPT actually use external data - this should help.
What is RAG, really?
Most explanations say: RAG = LLM + external knowledge
That’s technically correct, but completely useless.
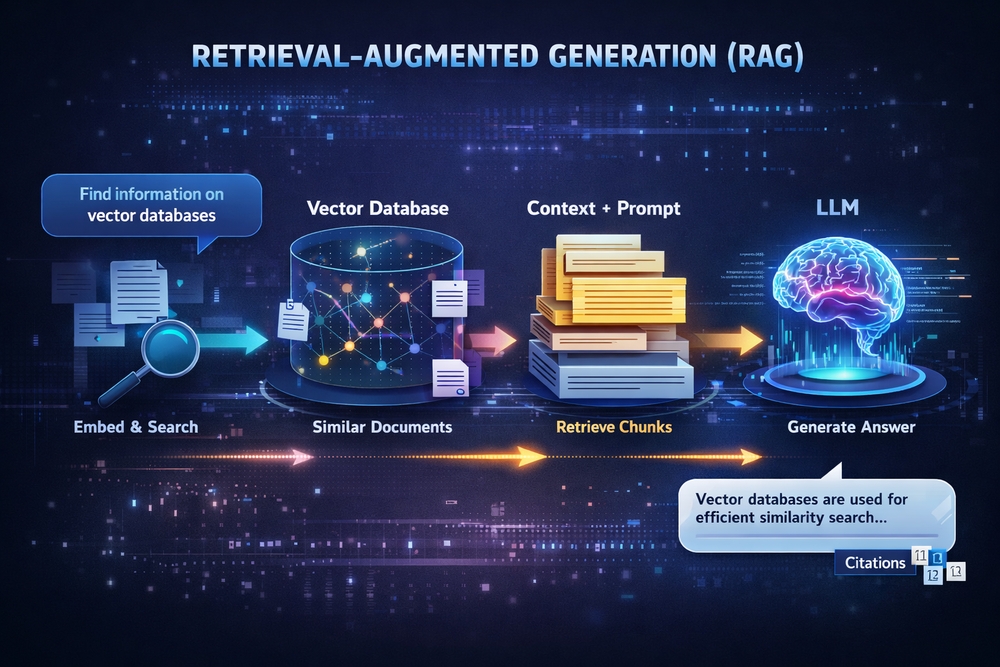
A better way to think about it is: RAG is a system that selects the right context and injects it into a model at the right time.
The LLM is not searching your data. It has no idea your data exists.
Your system does:
- find relevant pieces of information
- pass those pieces to the LLM
- force the LLM to answer only from that context
So the real system is:
User Query → Embedding → Vector DB → Retrieve → Prompt → LLM → Answer
That’s RAG.
Why I didn’t start with frameworks
Most people start with frameworks like LangChain and never understand what’s happening underneath.
I took the opposite approach: I built everything manually first.
That one decision changed everything.
Phase 1: Manual RAG
I started with:
- local text files
- simple loader
- naive chunking
- Gemini embeddings
- manual cosine similarity
- prompt construction
This helped me understand:
- how embeddings work
- how similarity works
- why chunking matters
Phase 2: Vector database
I moved to Chroma.
Now instead of scanning arrays manually: I had indexed retrieval.
This made the system:
- faster
- cleaner
- scalable
Phase 3: Real problems
Then came real engineering:
Incremental indexing
Instead of reprocessing everything: I used SHA256 hashing.
Deleted file handling
I synced DB with filesystem.
Better chunking
Moved from character-based to semantic chunking.
Tuning controls
Added:
- top_k
- threshold
- chunk size
- debug logs
Phase 4: Deep understanding
Vector DB is just: id + embedding + metadata + document
Nothing magical.
Phase 5: Tool layer
Added tool routing:
- list files
- show chunks
- reindex
Now system became: RAG + actions
This is foundation of agents.
Key insights
- Retrieval matters more than model
- Chunking defines quality
- Hashing enables correctness
- Frameworks hide complexity
- RAG is context engineering
What I built
- ingestion pipeline
- semantic chunking
- embeddings
- vector DB
- incremental indexing
- deletion sync
- retrieval tuning
- prompt engineering
- tool routing
This is not a toy system.
Alternatives
Chunking
- character
- paragraph
- sentence
- semantic
- LLM-based
Vector DB
- Chroma
- FAISS
- Qdrant
- pgvector
Retrieval
- keyword
- semantic
- hybrid
- reranking
Tools
- rule-based
- LLM-based
- function calling
Future path
- LangChain abstraction
- tool calling via LLM
- agent loops
- LangGraph
- hybrid search
- reranking
Final thoughts
LLM is not magic.
System design is.
RAG is not about adding data to LLM. It is about controlling context.
If you want to learn GenAI: build first, abstract later.
That’s how you actually understand.